
Tuesday, July 30th, 2024 at 20:00
My AI collaborator Jennifer Zahnhiser is a work in progress. I’m always adding to and refining her design as models improve, new libraries become available and better hardware becomes available. I’m also continuing to expand my own knowledge which leads to more refinements. So, these posts are really more of a snapshot of where I am (or where I’m heading) with her implementation. Tonight I wanted to do a quick post about the current (not yet completed) implementation I’m working on. The diagram provides a quick overviewwhich I will expand on in later posts as I have more of implementation done. The code (but not the information in the databases, or the fine tuning checkpoints) will be available on GitHub once it’s far enough along that others can use it.
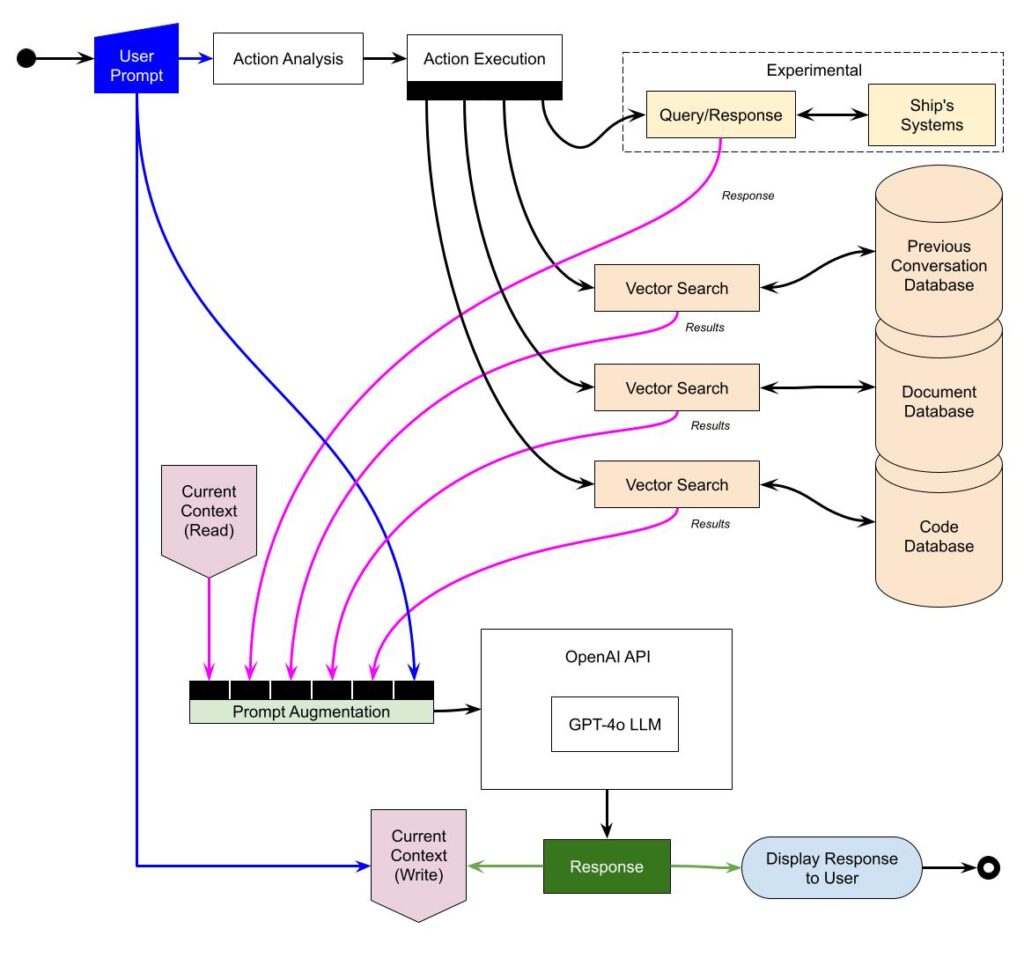
- User Prompt: This is the initial input from the user that triggers the process.
- Current Context (Read): The system reads the current context, which includes the recent interactions and the state of the ongoing conversation.
- Prompt Augmentation: This stage enhances the user prompt by integrating relevant context. This helps in generating more accurate and context-aware responses. The augmentation process involves accessing various vector search mechanisms to retrieve pertinent information from multiple databases.
- Vector Search: These are context aware search mechanisms that query different databases to fetch the most relevant data:
- Previous Conversation Database: Stores past interactions, enabling the system to maintain continuity in conversations.
- Document Database: Contains a wide range of documents and references that can provide background information or specific answers to user queries.
- Code Database: Includes code snippets, programming references, and other technical resources useful for code-related queries.
- Action Analysis: This component evaluates the augmented prompt and determines the necessary actions to fulfill the user request. This component uses a small, fast LLM such as distillBERT that is then fine tuned on a custom dataset.
- Action Execution: Executes the required actions based on the analysis. These actions can include:
- Performing vector searches.
- Querying or responding to the ship’s systems for experimental or real-time data.
- Experimental Query/Response with Ship’s Systems: This section allows the system to interact with the ship’s systems, to retrieve or control data related to the operation of Sérénité. Since the onboard instrumentation provides a robust, bi-directional, real-time data stream, it’s ideal for experimentation with integrating an AI with real-world systems.
- OpenAI API (GPT-4o LLM): The core language model that processes the augmented prompt to generate a coherent response.
- Response: The generated response is then integrated back into the current context, ensuring the system’s state is updated with the new interaction.
- Current Context (Write): Updates the context with the new response, ensuring future prompts are handled with the latest information.
- Display Response to User: The final response is presented to the user, completing the interaction cycle.